Learning Actively... An Experiment in Self-Study
I am an AI researcher and I spend a lot of time thinking about and developing more data-efficient models. For applications such as AI & biodiversity monitoring (my usual topic) and many others, access to labelled data and expert annotators is the critical bottleneck. Active Learning (AL) is a method to learn more efficiently with less data through careful selection of informative training samples. Check out this post to learn more about AL.
There are many parallels between model learning theory and our own learning. Both need a way to quantify uncertainty, assess competence, prioritise what to learn next, and know when to stop, all while balancing limited resources (e.g. compute or time/energy).
Let's explore this connection in more depth ⟶

Motivation
I encounter new and challenging concepts while trying to solve problems and reading papers, and like everyone I have limited time, energy and mental bandwidth (budget).
I have noticed that I learn best by doing. Attempting to code up a new method quickly surfaces misconceptions and gaps. As much as possible I try to implement concepts but this is extremely time consuming.
More recently, I have found LLM platforms to be very helpful in this process. Options like “learning mode” where you are asked questions and have to attempt an answer provide the same benefits, surfacing misconceptions. Additionally, it out-sources the assessment process and provides a custom learning path based on previous context, goals and your answers. The decision process around which concepts to allocate your time (budget) to and self-assessment, deciding when you are done (stopping-criterion), are themselves expensive and error prone tasks. *Aside: LLMs are not necessarily good external assessors given their sycophantic design.
Another benefit of these platforms is their breadth of knowledge, particularly useful given the “you don’t know what you don’t know” problem. If I have a problem I need to solve, as the learner, I don’t know the landscape of possible solutions (hypotheses). LLMs (+ search) have the necessary breadth of knowledge to, at the very least, identify promising starting points and links between concepts. AI (and active learning) doesn’t replace the learning process, it just provides a scaffold.
The AL formula
First, we need to clarify the terminology here. Active learning is not active learning: The educationalist definition of active learning relates to learner engagement e.g. debating a topic rather than passive listening. The machine learning definition refers to a data querying strategy. These fields have plenty of conflicting definitions (e.g. deep learning).
In this blog I will be exploring the design of the learning process, this is essentially “learning how to learn” and is called meta learning, a definition both can agree on hopefully ⟶
We start with a model (learner) in some initial state, maybe it is pre-trained on some existing data or randomly initialised. Our model provides inference on a set of unlabelled samples, providing some output for each (e.g. classification, detection, generative output etc). Most importantly, for each output there is also a utility score. This score quantifies the predicted value of labelling that sample and is generally a heuristic for the expected information gain. This process is often referred to as uncertainty sampling using metrics, such as entropy, which quantify the model’s uncertainty associated with its prediction. In practice, the utility score is more than simply uncertainty, some approaches may also consider the broader pool of candidate samples. This is an important process for batched-AL to reduce redundancy. Completing the loop, high utility samples are labelled and used for training, predictions and utility scores recomputed, and the process repeats until the budget is exhausted.
Now you are the model (learner), trying to understand a new concept. You have some initial state, a mental model of the space of concepts, however patchy. Your uncertainty, and perhaps too the difficulty in learning this new concept, is dependent on this space of concepts. A new concept, closely related to something you already understand is easy, while a concept built upon other new and unknown concepts is difficult. Your ability to learn and understand this target concept depends on your ability to efficiently map the space of related concepts, estimate utility, assess your understanding and update your hypothesis space. This is related to a connectivist view of pedagogy (learning through connections).
Constructing a Knowledge Graph
In the model example, it is assumed that we already have a pool of representative data. As a learner, we don’t have this, we have a problem to which we are trying to find a solution or maybe a loose idea of the target concept.
To start, we need to identify what our target concept is and where it fits within the landscape of related concepts. Here is the you don’t know what you don’t know problem in action. Identifying related concepts and formulating our problem into something learnable is, in itself, a challenge. We may already understand some related concepts but identifying these connections is non-trivial.
As mentioned, this is where LLMs are useful. Through their breadth of knowledge and ability to automate the search process, relevant solutions and concepts can be identified, all within the context of your specific application space. Below is an example of this, given a problem, some user information (e.g. background, goals etc) as well as a list of prior knowledge (e.g. existing graph), a graph of candidate concepts and their connections can be constructed. The demo app shown will be available soon.
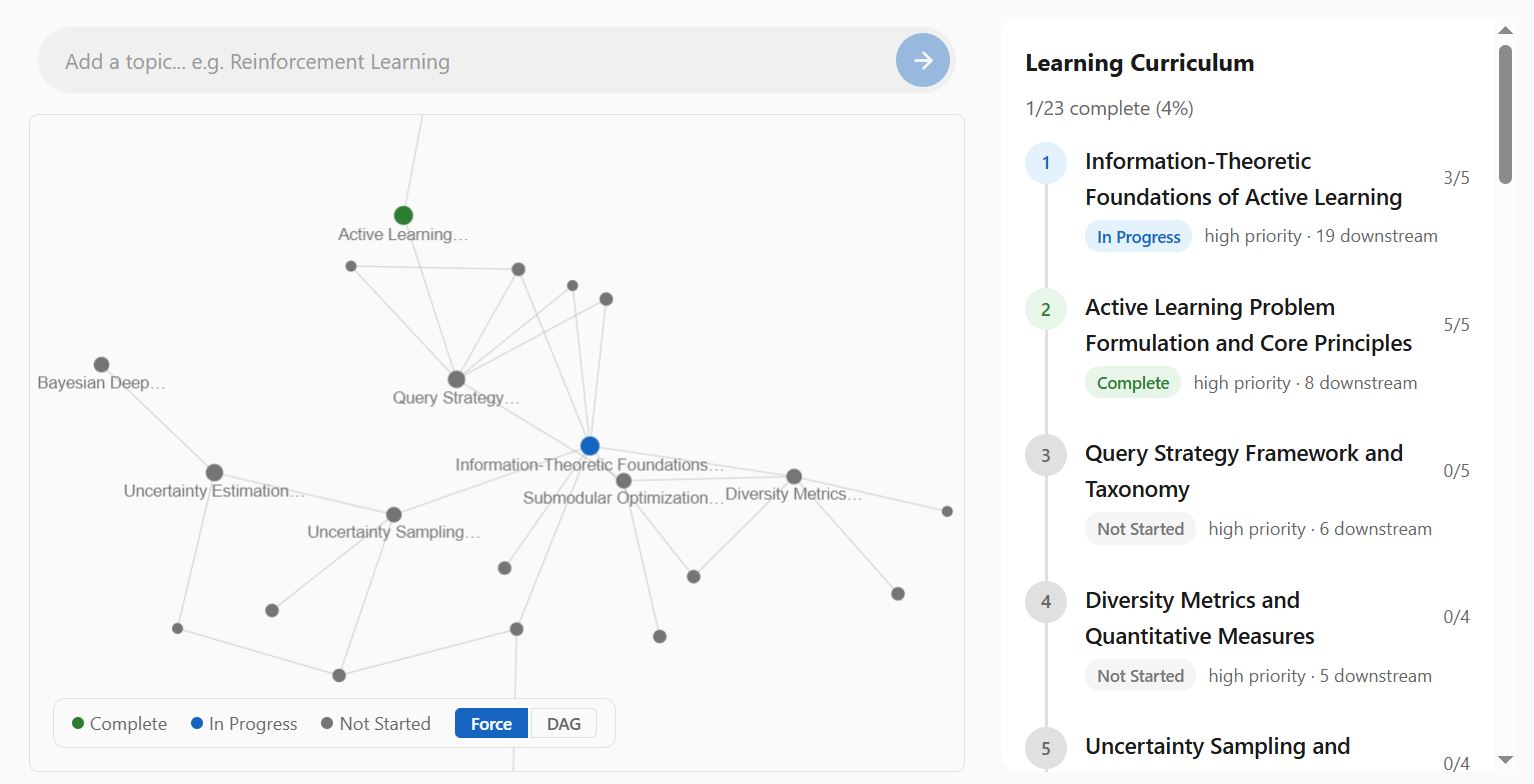
Measuring Utility
The concept of measuring utility maps quite nicely on to a graph. Concept nodes are linked together (edges); foundational concepts will have more edges, linking to down-stream concepts. We can represent this as a Directed Acyclic Graph (DAG) to visualise the way that foundational concepts branch and unlock down-stream concepts. This provides a natural entry point, an answer to the where to begin problem.
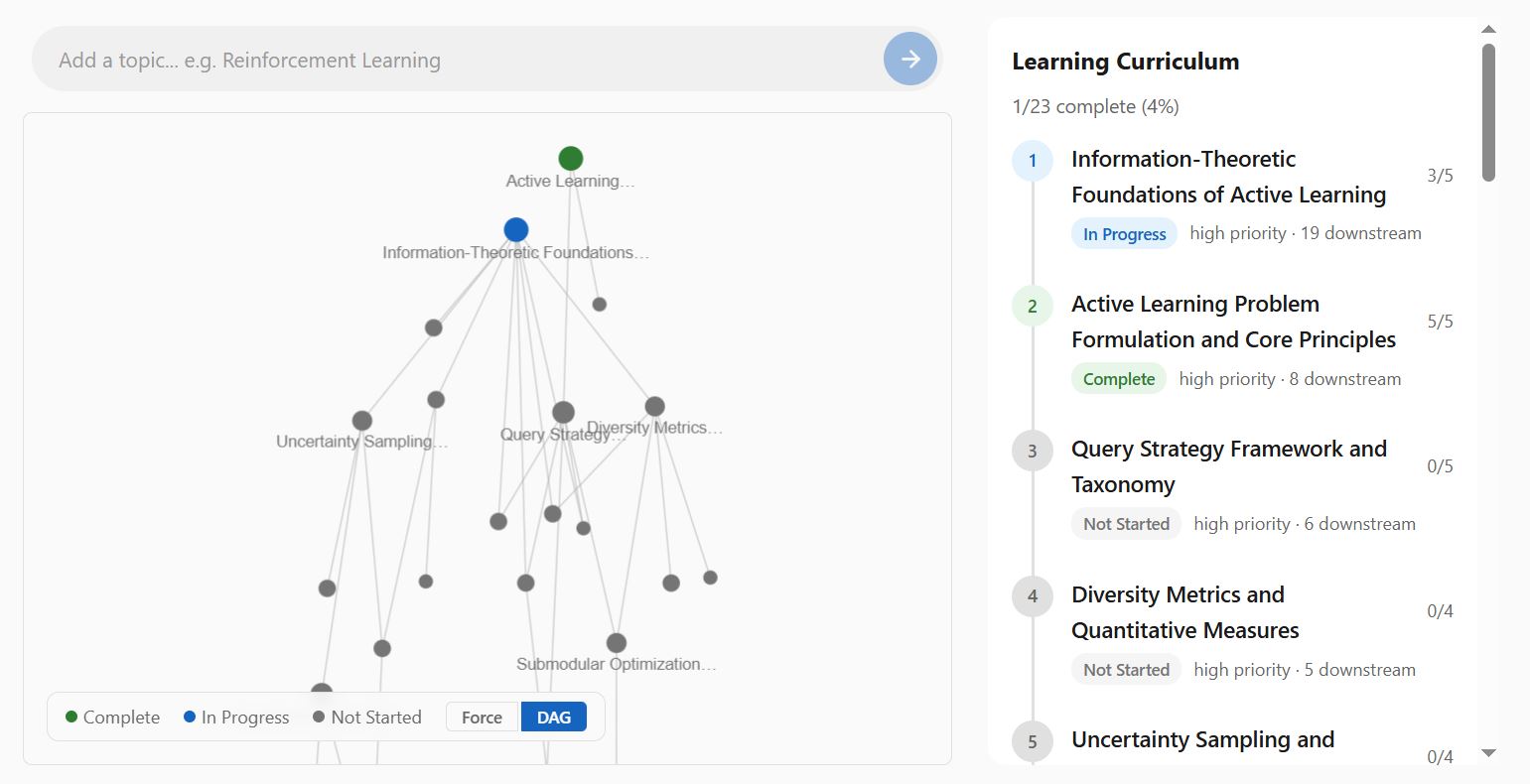
The graph can be refined through learner interactions. Learners may already understand certain concepts while others may not be a priority
Constructing a Curriculum
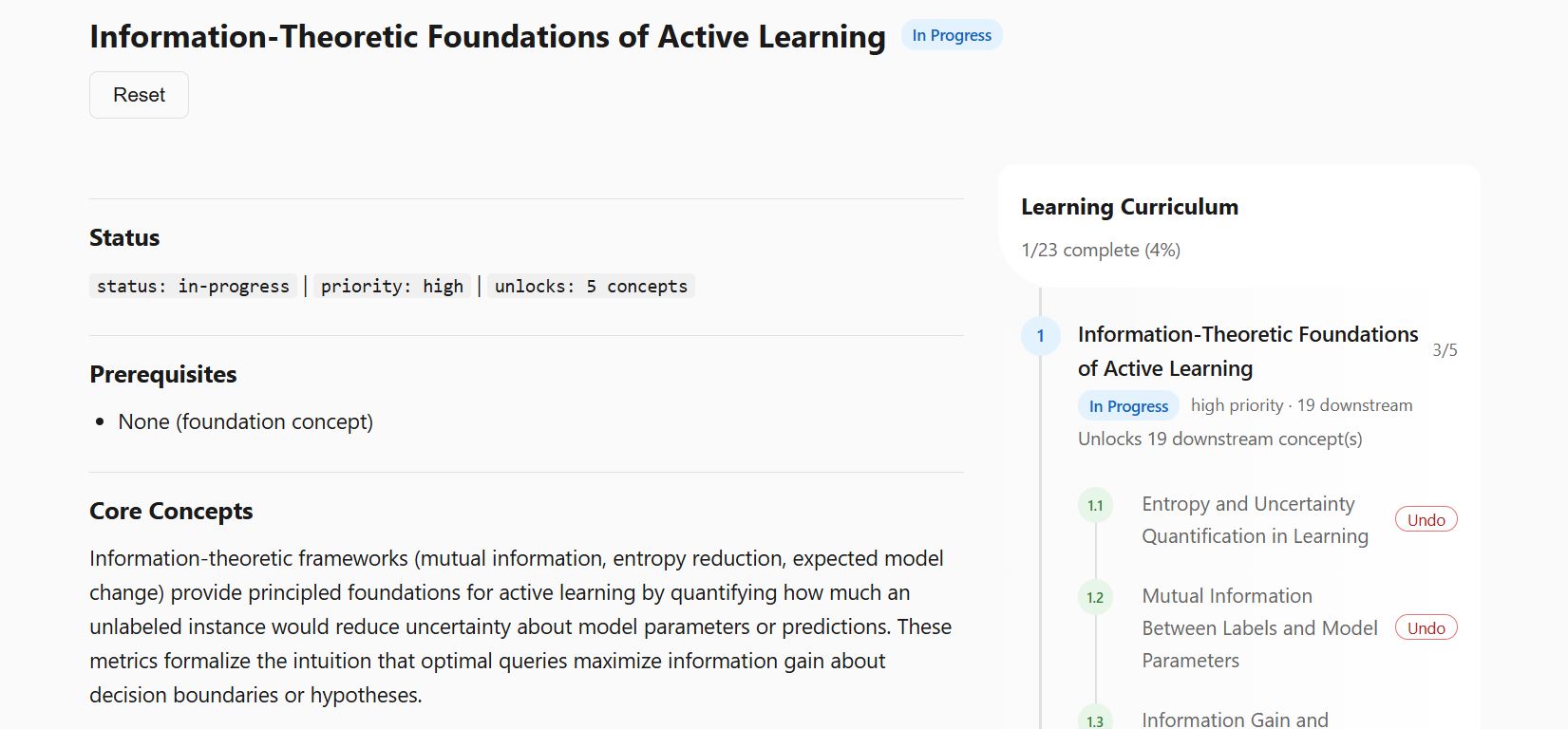
Given the graph connections and utility a curriculum can be constructed as the path of shortest traversal from foundational concepts to target concept. Each concept in itself may have additional sub-topics and pre-requisites.
At this stage the learning step is rather open-ended, which is not without issues. Currently, sub-topics contain:
- Self-assessment questions: If you already know the concept then move on.
- Attachments: Options to attach notes, papers and python notebooks (.ipynb) to concepts. I mentioned that I find coding a good way to learn, the app just provides a convenient scaffold between my knowledge graph and other resources. Think of it like Obsidian but with full integrated code and paper.
- Chat: A link with a pre-prepared prompt to start a learning-mode chat. This is an external link. I am hesitant to implement full chat features. This adds additional overhead to an otherwise simple app. I also think current LLMs do this perfectly fine.
Learning and the Link to AL
This analogy between active learning and our own learning is not one to belabour, however it is interesting to consider the similarity and differences:
The Data Space: A clear difference already highlighted is the graph construction step. Active learning is generally applied to a fixed pool of candidate samples, however for the learner, this pool is latent. In standard AL, the learner only influences which candidates are prioritised within a fixed pool. Here, learner interactions also shape which concepts enter the pool in the first place. An analogy here might be sensor placement, data collected from past sensors guide the placement of future sensors.
Measuring Utility: We have two ways to measure utility 1) The primary is based on the graph structure itself, measuring the utility of concepts by their connections to others and 2) User interactions with the concepts themselves (e.g. marking as complete). The connection here that closes the loop is that user interactions update the graph structure affecting the utility of concept nodes. Graph-based utility (centrality, edges) is a prior – it reflects the structure of the concept space before any learner-concept interaction. User-responses update this prior.
Assessment: Assessing user interactions and how they should update the graph is the most difficult step. In active learning, expert labelling of model responses is assumed to be reliable and for many tasks the prediction and label have a clear predefined structure. For example, which class does an image contain? Here the label is a free text response or discussion external to the app itself.
The screenshot shown here are a (work-in-progress) self-learning app I have developed to support my own learning and test these concepts. A demo will be released soon.